@שמואל5 כתב בבירור | מאגר מראי מקומות - ישיבת מיר:
לעבור על כל זה יקח לך הרבה זמן...
או פשוט ליצר סקריפט קטן שיעשה את כל העבודה...
@שמואל5 כתב בבירור | מאגר מראי מקומות - ישיבת מיר:
לעבור על כל זה יקח לך הרבה זמן...
או פשוט ליצר סקריפט קטן שיעשה את כל העבודה...
@asz כתב בבעיה | כמה הערות עיצוביות:
כי עבר כמה זמן עד שזה נכנס, ואת זה העתקתי מהמקור לפני השינויים שהיו,
כדאי לאכסן את הנתונים האלו בקובץ מסוים בקוד ומשם ישאבו את הנתונים גם בהגדרות וגם באודות שלא יצטרכו כל שינוי לשנות ב 2 מקומות
כדאי להעביר את ר.נבון לקראת סוף הרשימה זה נראה בעין יותר טוב שהשמות הארוכים עם הסוגריים של ההסברים נמצאים בסוף
אגב אתה עדיין לא מופיע במפתחים ...
עוד הערות שקשורים לעבודה שלך הרב @asz
הקישור לנדרים פלוס (מופיע גם באוצריא/תורמים וגם בחכמי לב) זה לא הקישור העדכני עם התמונה של אוצריא nedar.im/ezOd (אגב גם באודות זה לא עודכן משום מה)
הלחצנים הצטרף לעריכה והצטרף עכשיו לא פותחים את הקישור מתיקיית אוצרייא סייט כמו במסך אודות זה בכוונה ?
אגב באמת כבר הגיע הזמן להוסיף בתוכנה קישור לפורום אבל לדעתי זה לא אמור להיות בלחצן הצטרף לעריכה.
כמו כן באמת כדאי שיהיה הסבר שהתוכנה בקוד פתוח עם קישור לקוד המקור אבל לא חושב שהלחצן הצטרף עכשיו זה המקום, וחוץ מזה עדיף לקשר ישירות לארגון אוצריא https://github.com/Otzaria/otzaria ולא לקוד מקור של סיון שכבר לא מעודכן.
כמו כן כדאי להוסיף קישור והסבר לאתר עריכת הספרים, אולי מתחת למהדירי הספרים.
@דנדי כתב בעדכון | בעיות בגרסאות הDB? רק כאן, ורק אם הגרסה שלכם מעודכנת!!!:
[אגב מי זה שלמה בגיטהב זה שבנה את ההגדרות החדשות?]
לכאורה
@asz
@הבל-הבלים כתב בעדכון | בעיות בגרסאות הDB? רק כאן, ורק אם הגרסה שלכם מעודכנת!!!:
ניסית עכשיו שוב?
תמחק את תיקיית האינדקס.
ברור ניסתי כמה פעמים
@הבל-הבלים כתב בעדכון | בעיות בגרסאות הDB? רק כאן, ורק אם הגרסה שלכם מעודכנת!!!:
אני חושב שיש לך DB ישן!!!
עדכני
@הבל-הבלים
ואוו איזה הבדל אדיר בפתיחה והשימוש
חבל שעדיין לא הסתדר הש"ס בטקסט והצורת הדף בחלק מהספרים
אגב מה פשר השגיאות הבאות (נוצרו לי בלוג בגרסא הקודמת) מקדם אותך במשהוא ?
Instance of 'FlutterErrorDetails'Instance of 'FlutterErrorDetails'Instance of 'FlutterErrorDetails'Instance of 'FlutterErrorDetails'Instance of 'FlutterErrorDetails'PathNotFoundException: Cannot open file, path = 'תלמוד בבלי/סדר קדשים/מנחות' (OS Error: The system cannot find the path specified, errno = 3)PathNotFoundException: Cannot open file, path = 'תלמוד בבלי/סדר קדשים/מנחות' (OS Error: The system cannot find the path specified, errno = 3)PathNotFoundException: Cannot open file, path = 'תלמוד בבלי/סדר קדשים/מנחות' (OS Error: The system cannot find the path specified, errno = 3
@יהודי-צעיר כתב בעדכון | בעיות בגרסאות הDB? רק כאן, ורק אם הגרסה שלכם מעודכנת!!!:
באמת??
אם כן זה ממש הזוי!
@הבל-הבלים כתב בעדכון | בעיות בגרסאות הDB? רק כאן, ורק אם הגרסה שלכם מעודכנת!!!:
כמה שוקלת תיקיית האינדקס?
עכשיו אני אוחז שהאידקס באמת שוקל רק כ10 מ"ב 
@יאיר-דניאל
אם כבר יכול להיות פתרון יותר פשוט בלי צורך לנפח את קובץ ההתקנה
שבתהליך ההתקנה יבדוק אם כבר מותקן הרכיב המתאים
ואם לא יציג הודעה עם קישור להורדה
בגרסא האחרונה 669 יש באג בזכור ושמור שתקוע שעות על המסך טעינה עם העיגול המסתובב
אגב זה נראה שרוב הבעיות שהיו במעבר לDB כבר נפתרו ועכשיו הכל הרבה יותר יציב
לדוגמא יצירת אינדקס לקחה מחדש לי כשלוש דקות
שאפו לכל המפתחים על העבודה הרבה
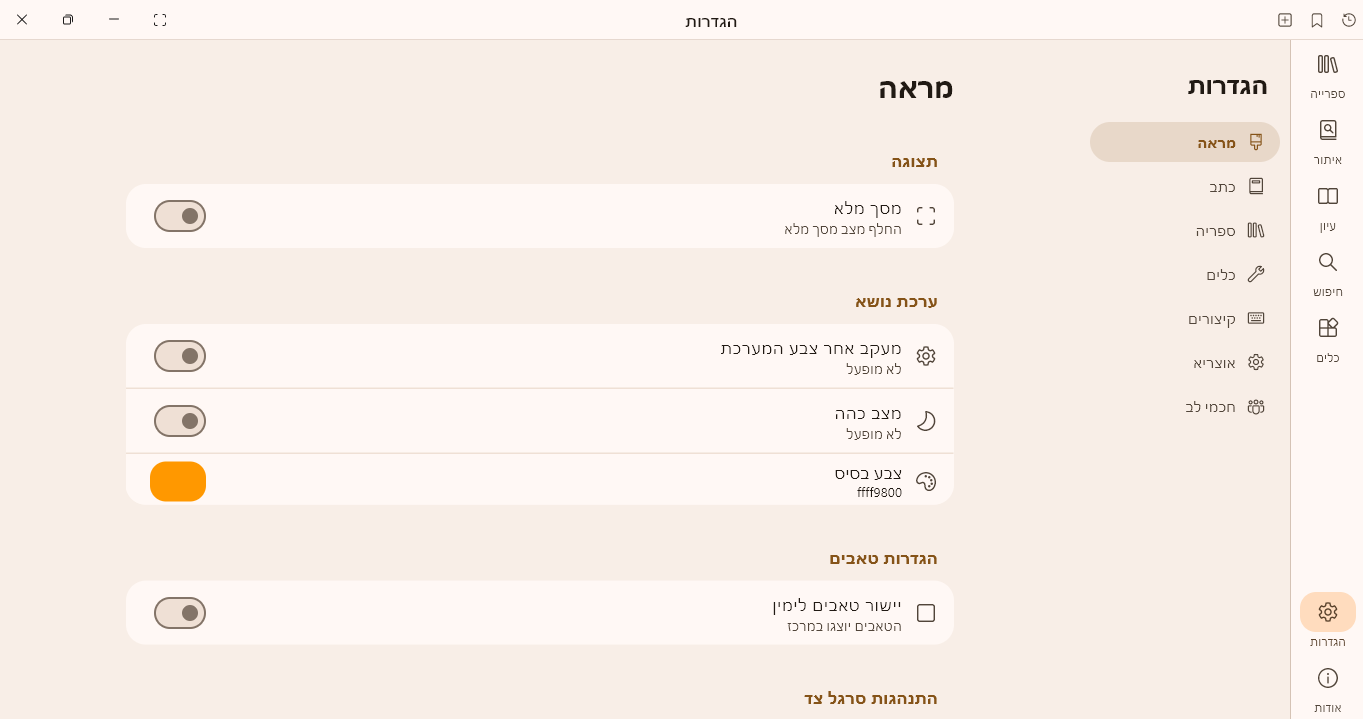
נ.ב. העיצוב החדש למסך הגדרות די יפה למרות שחלק מהטקסט שם צריך שיפור שהמשתמשים יבינו על איזה הגדרה מדובר אולי גם כדאי להוסיף חיפוש בהגדרות
למי שלא ראה עדיין את העיצוב החדש להגדרות מצו"ב תמונה
@פלמנמוני
זה מהקובץ errors.txt
Instance of 'FlutterErrorDetails'Instance of 'FlutterErrorDetails'Instance of 'FlutterErrorDetails'Instance of 'FlutterErrorDetails'Instance of
FlutterErrorDetails'Instance of 'FlutterErrorDetails'
@פלמנמוני כתב בעדכון | בעיות בגרסאות הDB? רק כאן, ורק אם הגרסה שלכם מעודכנת!!!:
זה אמור ליצור קובץ לוג לשגיאות (יתכן שהקובץ יווצר בתיקיית ההתקנה הרגילה)
ויקרא שם הקובץ שגיאות בישראל ?
@פלמנמוני כתב בבאג | התוכנה בגירסא החדשה איטית:
יתכן שכדאי שתעשו הסרה לגירסה הקודמת
לא איכפת לי...
אבל אם זה קשור לאחד הגרסאות האחרונות של הDB ניחא, אבל אם זה קשור למהדורות טקסט מומלץ לפתור את הבעייה מהשורש שתוכל לשחרר עדכון לכלל המשתמשים בלי צורך בהסרה והתקנה.
אגב גם הלחצנים של להגדיל ולהקטין את הטקסט בתצוגה מקדימה לא עובדים ב PDF מומלץ בהזדמנות לסדר או להסירם.

@פלמנמוני כתב בבאג | התוכנה בגירסא החדשה איטית:
את מי?
במסך ספרייה בתצוגה מקדימה של ספר טקסט בלחיצה כפולה על התצוגה מקדימה נפתח הספר, בלחיצה כפולה על ספר PDF בתצוגה מקדימה לא נפתח הספר.
@פלמנמוני
ובכן ...
מהירות פתיחת קבצי PDF השתפרה
כמו כן מהירות הגלילה השתפרה
המעבר בין מהדורת הטקסט לPDF והפוך עובד (רק הטקסט לא מוצג  )
)
אגב זה די יפה שרואים את הקובץ גם בתצוגה מקדימה במסך ספרייה חבל שלחיצה כפולה לא פותחת אותו
חלק מהבאגים שקשורים לתקיעת הPDF לא הסתדרו...
הקובץ נפתח תמיד בעמוד הראשון ולפעמים גם כשאני אוחז בדף מסוים ועובד בין הכרטיסיות הוא יכול לקפוץ שוב לדף הראשון
מרגע של שגיאה או תקיעה כלשהיא בהצגת הPDF התוכנה נשארת לעבוד ברקע גם בסגירתה, כמו קודם
אגב עכשיו פתיחת הדף היומי לא עובד לא ממסך ספרייה ולא מלוח שנה
ממסך לוח שנה לפעמים מופיעה השגיאה לא נמצא
לענ"ד קשור לפתיחת התוכנה בדף מסוים למרות שכותב לא נמצא...

פתיחת דף היומי ממסך ספרייה לא נפתח אבל התוכנה מאחורי הקלעים מנסה לפתוח אותו וזה גם גורם לתקיעה.
יש לציין שבהחלט יש התקדמות בגרסא הזאת שהרבה פחות נתקע, וגם לא נתקע כבר ברגע הראשון...
יש לי תאוריה מעניינת...
הבעייה שגורמת לתוכנה לצרוך כזה הרבה משאבים ולהמשיך לעבוד גם אחרי הסגירה קשורה לשגיאה כלשהיא בהצגת PDF כלשהוא...
אם אני פותח את התוכנה וסוגר בלי לצרוך שום PDF הכל עובד תקין.
ברגע שאני מתחיל להתעסק עם PDF מתחילים התסמינים גם אחרי שאני סוגר את כל הכרטיסיות עם ה PDF וגם אם הPDF לא נתקע בפועל, התוכנה ממשיכה לדלוק ברקע גם לאחר סגירה וממילא ממשיכה לצרוך משאבים, וא"א לפתוח את התוכנה מחדש עד לסגירתה במנהל המשימות.
בעיות שאני רואה בעין בפתיחת PDF
טעינת PDF איטית
פתיחת הPDF תמיד בדף מספר 1 וגם אי אפשר לקפוץ עמודים בלחצן הזן מספר דף
גלילה למטה עם העכבר מאוד מאוד איטית
בגלילה מהירה עם החיצים או הפס גרירה טעינת ה PDF נתקע להרבה זמן או לצמיתות כולל PDFים אחרים שאני ינסה לפתוח
אם אני מחכה קצת זמן ורק אז מתחיל לגלול מהר את העמוד עם החיצים או הפס גרירה אז זה מצליח לגלול את העמודים הקרובים אבל אם אני גולל קצת יותר מזה אז כל ה PDF נתקע ונהיה לבן
יש באג קטן בגלילה עם חץ אחורה שהעמוד כאילו זז הצידה. לתשומת לב @פלמנמוני אבל לא חושב שהבאג הזה אשם בשאר התקיעות
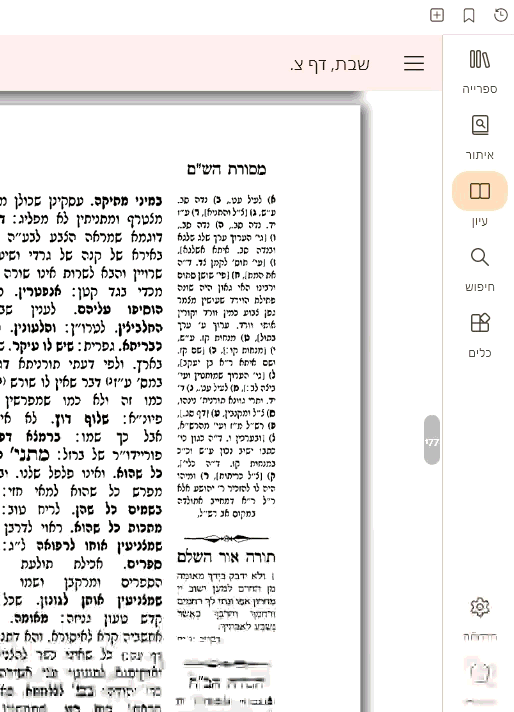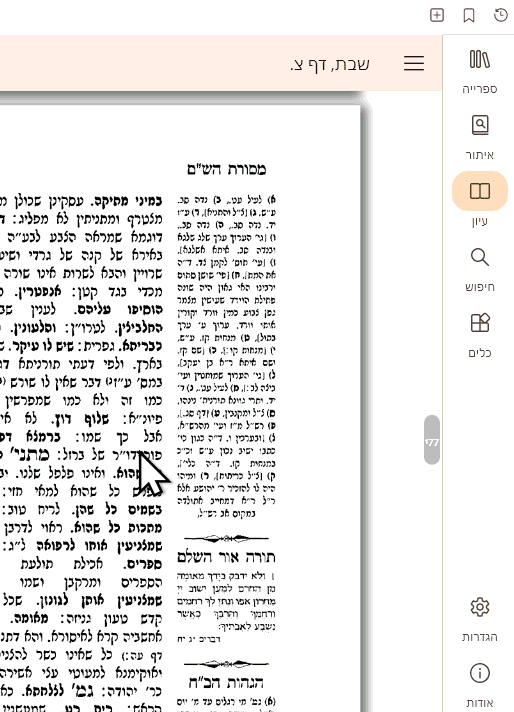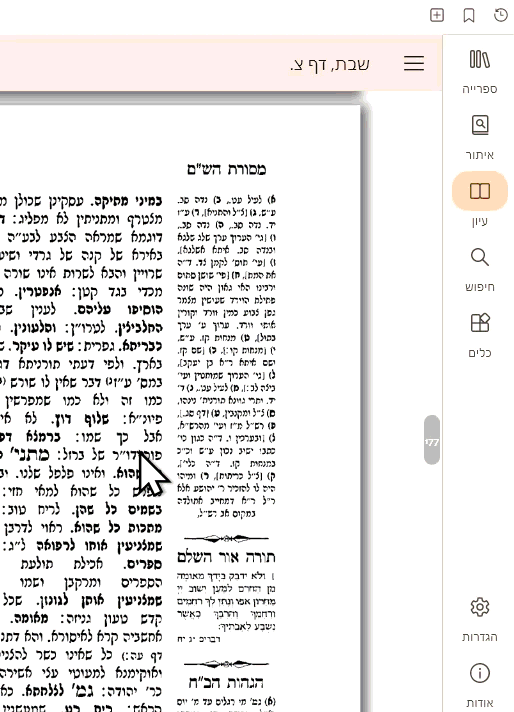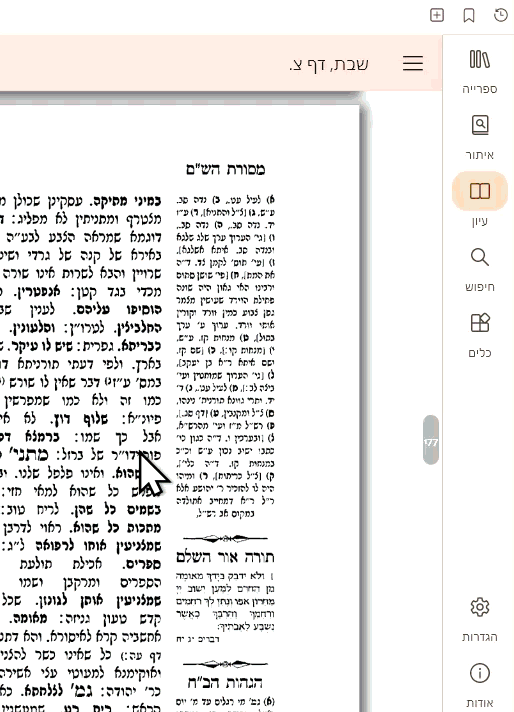
מסתבר שיש עוד שגיאות מאחורי הקלעים אבל אין לי דרך לדעת בלי לוגים...
@פלמנמוני כתב בבאג | התוכנה בגירסא החדשה איטית:
וגם הלחצן של הדף היומי במסך ספרייה
זה אני יודע
הקטע המעניין שהלחצן דף היומי בלוח שנה כן עובד
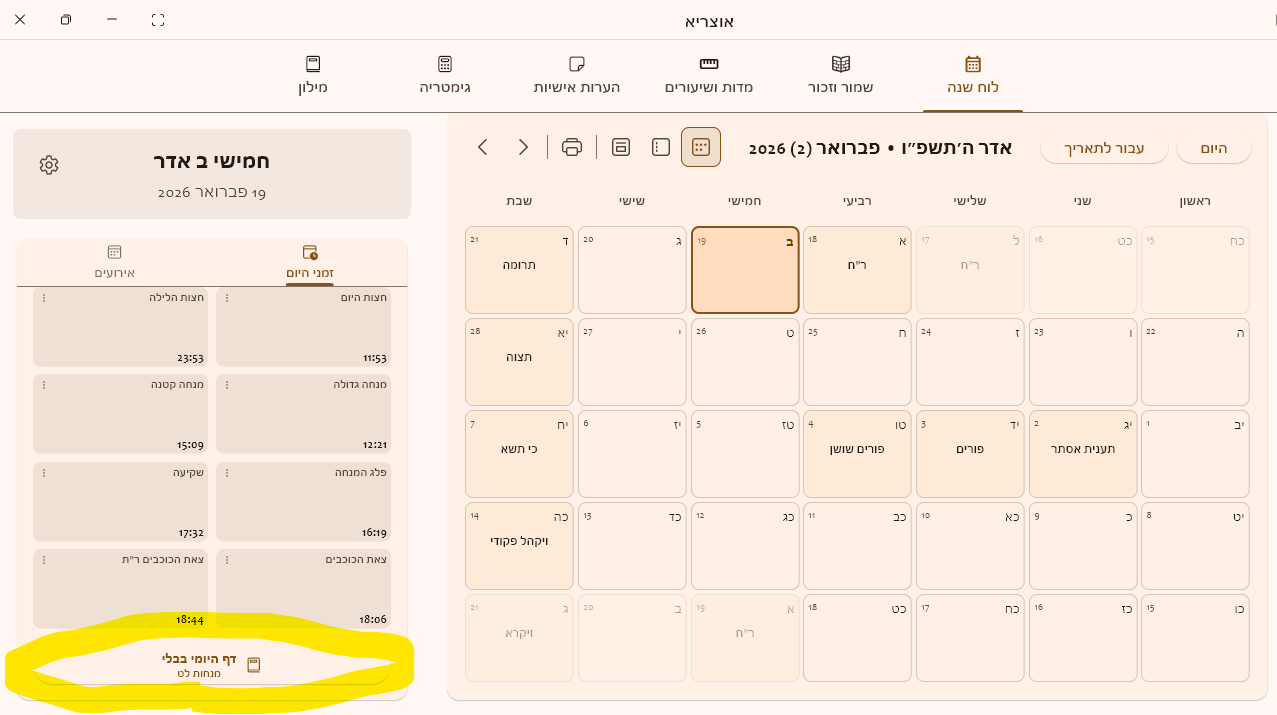
אתה בטוח שזה קשור לDB או לגרסא האחרונה ?
עכ"פ ב"ה שחזר לעבוד ונעלם הריבוע האפור ההוא
למרות שחוץ מהבאגים שדיווחתי מזמן באיסוס לגבי החלפת גופנים שעדיין לא התפנו לסדר את זה.
יש באג בבחירת טווח הדפסה שבספרים מסוימים משום מה הוא נשאר תמיד על המינימלי גם כשמגדירים את כל הספר

אגב שמת לב ששינו את הטווח הדפסה לשורות במקום מקטעים ?
@פלמנמוני כתב בבאג | התוכנה בגירסא החדשה איטית:
אצלי עובד
אני חושב שלא יהיה ברירה ולצורך איתור הבעיות שמופיעות רק אחרי קימפול ולא בהרצת הקוד הפתרון יהיה להוסיף לוגים לרוב הקוד ואז יהיה דרך לבודד תקלות
@פלמנמוני כתב בבאג | התוכנה בגירסא החדשה איטית:
הPDF עובד!
לא
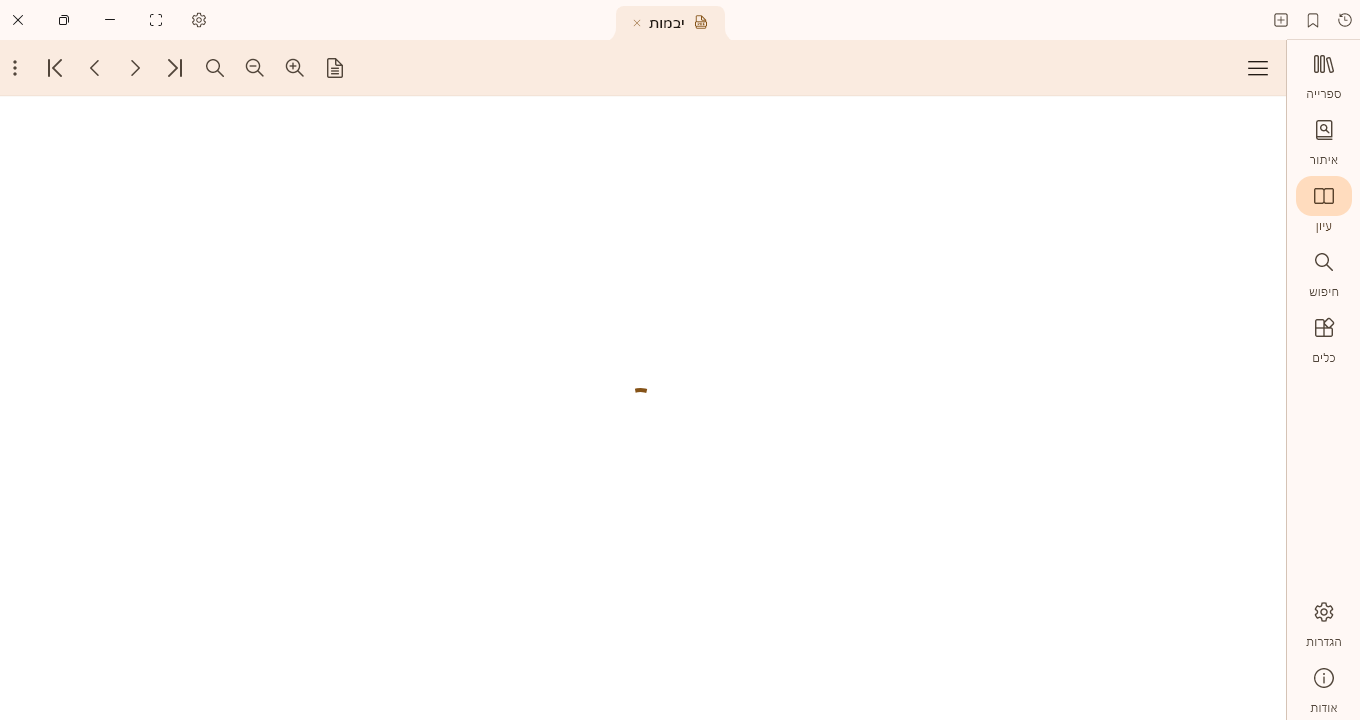
אהה וגם הש"ס טקסט לא עובד
וגם הלחצן של הדף היומי במסך ספרייה
וגם הלחצן למעבר מש"ס טקסט לש"ס PDF
ובגרסא האחרונה 547 עם ה DB החדש
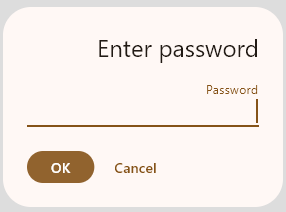
לא מוצג בכלל לא קבצי טקסט ולא PDF שדורשים פתאום סיסמא לפתיחה
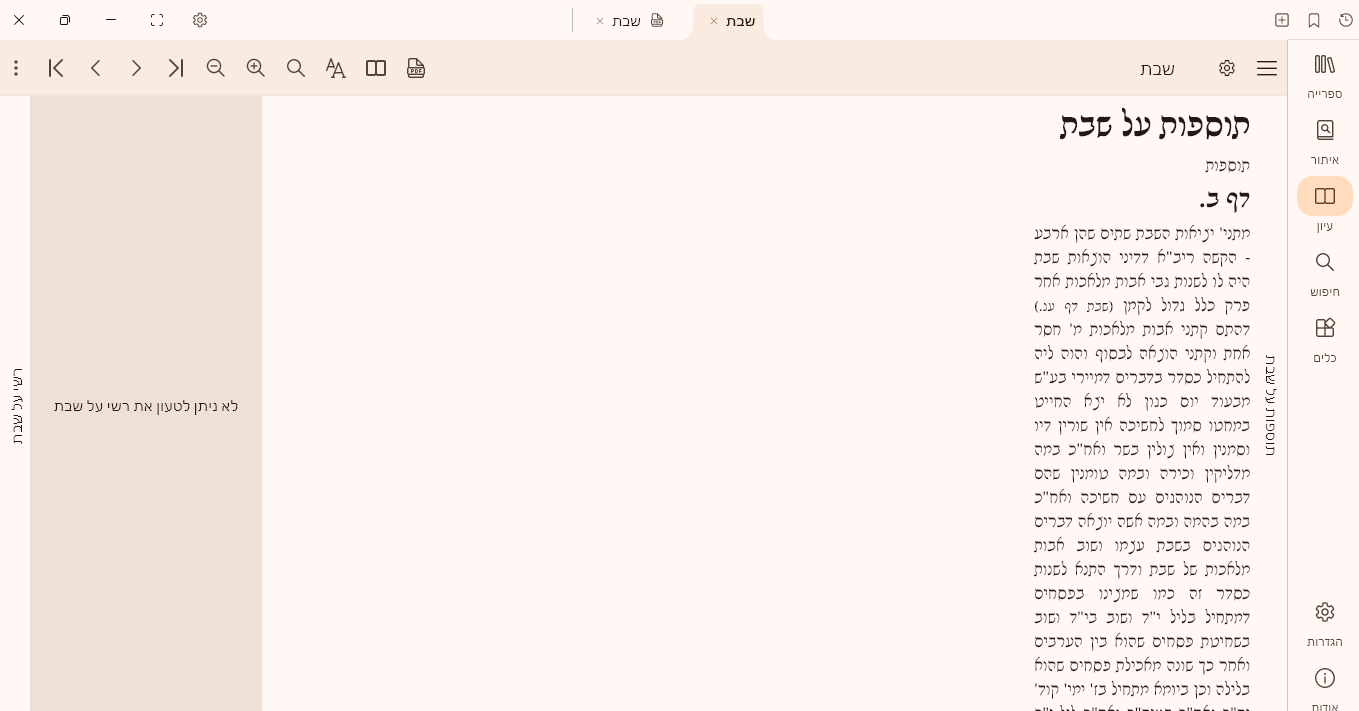
בצורת הדף מופיע חלקי ממש
@האדם-החושב רעיון טוב....
import requests
import json
import time
import re
from google.colab import files
# --- הגדרות ---
API_URL = "https://nakdan-u1-0.loadbalancer.dicta.org.il/api"
CHUNK_SIZE = 1500
LOG_FILE = "debug_log.txt"
JSON_FILE = "abbreviations_result.json"
# משתנים גלובליים
logs = []
all_potential_misses = set() # מאגר לכל המילים שלא פוענחו
def log(message):
timestamp = time.strftime("%H:%M:%S")
full_msg = f"[{timestamp}] {message}"
print(full_msg)
logs.append(full_msg)
def smart_chunking(text, max_size):
"""חלוקה חכמה לפי סופי שורות"""
chunks = []
current_chunk = []
current_length = 0
lines = text.split('\n')
for line in lines:
line_len = len(line) + 1
if current_length + line_len > max_size:
if current_chunk:
chunks.append("\n".join(current_chunk))
current_chunk = []
current_length = 0
if line_len > max_size:
# טיפול בשורה ארוכה מאוד
words = line.split(' ')
temp_chunk = []
temp_len = 0
for word in words:
if temp_len + len(word) + 1 > max_size:
chunks.append(" ".join(temp_chunk))
temp_chunk = []
temp_len = 0
temp_chunk.append(word)
temp_len += len(word) + 1
if temp_chunk:
current_chunk = temp_chunk
current_length = temp_len
else:
current_chunk.append(line)
current_length += line_len
else:
current_chunk.append(line)
current_length += line_len
if current_chunk:
chunks.append("\n".join(current_chunk))
return chunks
def call_api(data_payload):
"""פונקציה גנרית לקריאה ל-API"""
headers = {"Content-Type": "application/json;charset=UTF-8"}
try:
response = requests.post(API_URL, json=data_payload, headers=headers, timeout=45)
if response.status_code == 200:
return response.json()
except:
pass
return None
def strip_prefixes(word):
"""
מנסה להסיר אותיות שימוש (מש"ה וכל"ב) מתחילת המילה
מחזיר את המילה הנקייה אם נשאר בה גרשיים, אחרת מחזיר None
"""
# מסיר אותיות מ/ש/ה/ו/כ/ל/ב/ד מתחילת המילה, רק אם יש אחריהן עוד גרשיים
# למשל: ב"המק -> המק | ו"יוסף -> יוסף
clean = re.sub(r'^[משהוכלבד]+', '', word)
# אם נשארנו עם מילה שיש בה גרשיים והיא לפחות 2 תווים
if '"' in clean and len(clean) >= 2:
return clean
return word # אם אי אפשר לנקות, מחזיר את המקור
def retry_missed_words(missed_words_list, existing_results):
"""
מנגנון הזדמנות שנייה: לוקח מילים שנכשלו, מנקה אותיות שימוש ושולח שוב
"""
if not missed_words_list:
return existing_results
log(f"🔄 מתחיל סבב ב' (Retry) עבור {len(missed_words_list)} מילים שלא פוענחו...")
# מיפוי בין המילה הנקייה למילה המקורית
# דוגמה: {'המק': 'ב"המק'}
clean_to_original = {}
batch_text = []
for word in missed_words_list:
clean_word = strip_prefixes(word)
if clean_word != word: # רק אם היה שינוי
clean_to_original[clean_word] = word
batch_text.append(clean_word)
else:
# מנסים לשלוח גם את המקור שוב, אולי כבודד יצליח
batch_text.append(word)
clean_to_original[word] = word
# שולחים במנות של 500 מילים כדי לא להעמיס
chunk_size = 500
new_found_count = 0
for i in range(0, len(batch_text), chunk_size):
batch = batch_text[i:i+chunk_size]
text_string = " ".join(batch) # שולחים כרשימת מילים
payload = {
"task": "abbrexp",
"data": text_string,
"useTokenization": True,
"genre": "rabbinic"
}
data = call_api(payload)
if data and 'data' in data:
for item in data['data']:
if 'abbreviation' in item and item['abbreviation']:
abbr = item['abbreviation']
found_clean_word = abbr.get('word')
options = abbr.get('options')
if found_clean_word and options:
# אנחנו צריכים למצוא מה הייתה המילה המקורית (עם האותיות שימוש)
# ה-API מחזיר את המילה שהוא מצא (למשל "המק")
# אנחנו צריכים לשמור את התוצאה תחת המפתח המקורי "ב"המק"
# חיפוש הפוך פשוט (יתכן פספוס קטן אם יש כפילויות, אבל זניח)
original_word = clean_to_original.get(found_clean_word)
if original_word:
existing_results[original_word] = options
new_found_count += 1
time.sleep(0.2)
log(f"✅ סבב ב' הסתיים: הוצלו עוד {new_found_count} ראשי תיבות!")
return existing_results
# --- גוף התוכנית ---
print("אנא בחר קובץ טקסט...")
uploaded = files.upload()
if uploaded:
input_filename = next(iter(uploaded))
log(f"הקובץ {input_filename} נטען.")
with open(input_filename, 'r', encoding='utf-8') as f:
full_text = f.read()
chunks = smart_chunking(full_text, CHUNK_SIZE)
log(f"מתחיל עיבוד ב-{len(chunks)} מקטעים...")
final_results = {}
# שלב 1: מעבר ראשי
for i, chunk in enumerate(chunks):
# זיהוי פוטנציאלי במקטע (מילים עם גרשיים)
words_in_chunk = set(re.findall(r'\b[א-ת]+"[א-ת]+\b', chunk))
payload = {
"task": "abbrexp",
"data": chunk,
"useTokenization": True,
"genre": "rabbinic"
}
data = call_api(payload)
found_in_chunk = set()
if data and 'data' in data:
for item in data['data']:
if 'abbreviation' in item and item['abbreviation']:
abbr = item['abbreviation']
word = abbr.get('word')
options = abbr.get('options')
if word and options:
final_results[word] = options
found_in_chunk.add(word)
# חישוב מה התפספס במקטע הזה
missed = words_in_chunk - found_in_chunk
all_potential_misses.update(missed)
print(f"\rעיבוד: {int((i+1)/len(chunks)*100)}% (נמצאו: {len(found_in_chunk)}, חשודים כפספוס: {len(missed)})", end="")
time.sleep(0.1)
print("\nסיימנו סבב ראשון.")
# שלב 2: ניסיון הצלה
# מסננים מילים שכבר נמצאו (למקרה שהן הופיעו במקטע אחר וכן זוהו)
really_missed = [w for w in all_potential_misses if w not in final_results]
if really_missed:
final_results = retry_missed_words(really_missed, final_results)
# שמירה
log(f"סה\"כ ראשי תיבות מפוענחים: {len(final_results)}")
with open(JSON_FILE, 'w', encoding='utf-8') as f:
json.dump(final_results, f, ensure_ascii=False, indent=4)
with open(LOG_FILE, 'w', encoding='utf-8') as f:
f.write("\n".join(logs))
files.download(JSON_FILE)
files.download(LOG_FILE)
והנה התוצאה
ראשי תיבות.json
מקווה שיצרתי את ה JSON במבנה הנכון....
בגרסא האחרונה 546 צורת הדף עובד לי בש"ס אבל לא בתנ"ך לא מופיע שום מפרש וגם לא נותן לבחור
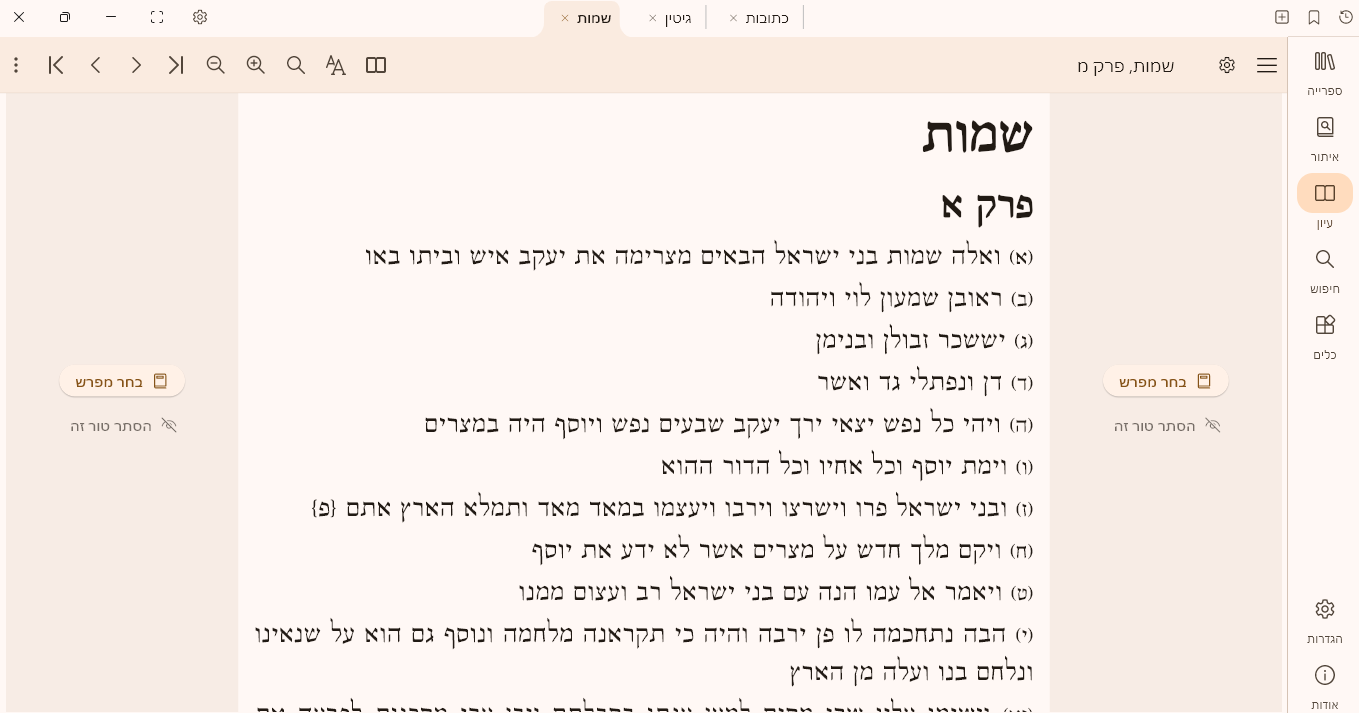
גם הלחצן לעבור בש"ס מצורת הדף לPDF לא עובד, וגם לא הלחצן של דף היומי מדף הבית