https://abbreviation.dicta.org.il/
אפשר לעבוד מול הapi שלהם אם יש למישהו רשימה של ראשי תיבות בלי פיענוח.
https://abbreviation.dicta.org.il/
אפשר לעבוד מול הapi שלהם אם יש למישהו רשימה של ראשי תיבות בלי פיענוח.
@יום-חדש-מתחיל
פרי עץ חיים.rar
import io
import json
import re
import zipfile
from pathlib import Path
import requests
from tqdm import tqdm
BASE_URL = "https://files.dicta.org.il/prietshaim/"
def get_toc() -> list[dict]:
url = BASE_URL + "pages.json"
response = requests.get(url)
return response.json()
def get_page_content(page: str) -> dict:
response = requests.get(BASE_URL + page)
if page.endswith(".zip"):
with zipfile.ZipFile(io.BytesIO(response.content)) as z, z.open(z.namelist()[0]) as f:
return json.loads(f.read().decode("utf-8"))
return response.json()
def process_page(output_file: io.TextIOWrapper, content: list[dict]) -> None:
for entry in content:
if 'display' not in entry:
output_file.write(entry['str'])
continue
for i in entry['display']:
val = i["c"]
heading = i.get("heading", False)
bold = i.get("bold", False)
if heading is True:
output_file.write(f"<big>{val}</big>")
elif bold is True:
output_file.write(f"<b>{val}</b>")
else:
output_file.write(val)
def main() -> None:
book_name = "פרי עץ חיים"
author = ""
target_file_path = Path(f"{book_name}.txt")
toc = get_toc()
with target_file_path.open("w", encoding="utf-8") as output_file:
output_file.write(f"<h1>{book_name}</h1>\n{author}")
for entry in tqdm(toc, total=len(toc)):
if entry["type"] == "index":
continue
page = entry["fileName"]
display_name = entry["displayName"]
output_file.write(f"\n<h2>{display_name}</h2>\n")
content = get_page_content(page)
process_page(output_file, content["tokens"])
with target_file_path.open("r", encoding="utf-8") as output_file:
content = output_file.read()
content = re.sub(r'\n+', '\n', content)
with target_file_path.open("w", encoding="utf-8") as output_file:
output_file.write(content)
if __name__ == "__main__":
main()
אגב, בזכות זה חקרתי קצת יותר את האתר של דיקטה ויתכן שיש דרך להוריד את הספרים שעדיין לא ערכו עם ירידות שורה, הדגשות וכו'.
@נתנאל זה סה"כ דף html (100% קלוד) שמשמש כסייר קבצים....
@י.-פל. כתב בלהורדה | חדש! מאגר גיטאב - לספרים מותאמים לאוצריא:
בעבר היתה יוזמה ליצירת צורת הדף כHTML, שזה בעצם טקסט פשוט שמעוצב בצורת הדף, זה קל (משהו כמו אלפית מPDF), ומהיר, אבל נראה לי דהם לא התקדמו בזה.
@האדם-החושב
@י.-פל. אפשר לתקן ... רק תגיד מה השגיאות.
במתמחים זה עבד מצויין, הבעיה היא בחיבור המשתמש לפורום כאן, אולי שינו משהו בהגדרות אבטחה של הפורום?
@יום-חדש-מתחיל זה יהיה עד העדכון הבא של ספריא, תיאורטית אפשר לעדכן עכשיו אבל אני מחכה לראות מה יצא עם עבודתו של לא מתייאש (שתפתור את בעיית הלינקים היתומים).
@יום-חדש-מתחיל כך זה הגיע במקור.
צריך לכתוב סקריפט שימיר את הכל לתווים סטנדרטיים.
@הבל-הבלים יש שמות שלא קיימים בכלל
יש שמות שלא הובאו בצורה נכונה
השמות נשאבו משמות התיקיות, לא מהמקור.
לכאו' רוב השמות תקינים אבל צריך לשים לב.
@יום-חדש-מתחיל
@הבל-הבלים כן, אבל הבעיה היא שהשמות שם נשאבו בצורה לא תקנית.
כל הנושא הזה נהיה בלאגן אחד גדול
רשימת המחברים שצריכים בדיקה
רשימת המחברים הפסולים
רשימת המחברים הכשרים
@יום-חדש-מתחיל מבקש הספר.
מהי תוכנת אוצריא?
@יום-חדש-מתחיל כדאי להדגיש שיביאו גם לינקים למקומות שבהם יש את הספר.
בכלים ובתפריט ימני של בחירת טקסט
@הבל-הבלים כלומר?
@צדיק-וטוב-לו @י.-פל.
יש בתיקיית ההתקנה של תורת אמת (ToratEmetInstall) תיקייה בשם Dictionaries ובתוכה קובץ בשם FinalDictionary.txt.
import json
from collections import defaultdict
from pathlib import Path
dict_source = {
0: "מילון שיח ישראל",
1: "מילון פשיטא",
2: "מושגים ואישים",
3: "מפירוש אונקלוס על התורה"
}
dict_all = defaultdict(list)
dict_path = Path(r"C:\Users\User\Documents\ToratEmetInstall\Dictionaries\FinalDictionary.txt")
output_path = Path("Dictionary.json")
with dict_path.open("r", encoding="windows-1255") as f:
content = f.read()
lines = content.split("\n")
for line in lines:
line = line.strip()
if not line:
continue
if not line[0].isdigit():
continue
source = dict_source[int(line[0])]
key, value = line[1:].strip().split("=", maxsplit=1)
dict_all[source].append({key: value})
with output_path.open("w", encoding="utf-8") as f:
json.dump(dict_all, f, indent=2, ensure_ascii=False)
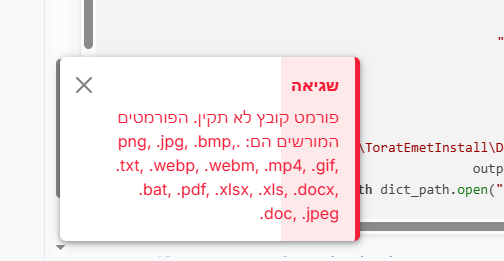
משום מה קובץ json הוא לא אחד מסוגי הקבצים שניתן להעלות לפורום.[Dictionary.json](פורמט קובץ לא תקין. הפורמטים המורשים הם: .png, .jpg, .bmp, .txt, .webp, .webm, .mp4, .gif, .bat, .pdf, .xlsx, .xls, .docx, .doc, .jpeg)
@ע-ה-דכו-ע